Обеспечение бесперебойной работы вашего экземпляра Jira Server является обязанностью любого хорошего администратора Jira. С нашими ограничениями на обслуживание вы покрыты, и 99,9% из вас никогда не испытают эти ограничения, они применяются только в действительно исключительных случаях.
|
Лимит |
Сервер |
Пример того как достичь этого лимита |
|
Компонентов на правило |
65 |
Более 65 условий, веток и действий для одного правила |
|
Новые подзадачи на действие |
100 |
Запускает создание более 100 подзадач |
|
Поиск задач |
1000* |
Запланированный поиск JQL, который недостаточно оптимизирован и возвращает более 1000 проблем.
* На сервере это число определяется свойством конфигурации jira.search.views.default.max. Это можно настроить и ограничить количество задач, возвращаемых при глобальном поиске в Jira. |
|
Одновременное выполнение запланированных правил |
1 |
Запланированное правило, выполнение которого занимает более 5 минут, запланированное каждые 5 минут. Допускается только одно одновременное выполнение этого правила. |
|
Элементы в очереди по правилу |
25000 |
Дополнительную информацию см. в разделе ниже об ограничении элементов в очереди. |
|
Элементы в глобальной очереди |
100000 |
Подобно элементам в очереди для каждого правила, но применяется к правилам, которые выполняются в вашем экземпляре Jira во всем мире. |
|
Ежедневное время обработки |
120 минут |
Правило выполняется каждые 5 минут, и каждое выполнение занимает более 5 секунд (в облаке). Это может иметь место, если ваше правило, например, говорит о медленных внешних системах. |
|
Время обработки в час |
100 минут |
Настройте несколько правил, которые прослушивают события задач и выполняют массовую операцию, которая выполняет эти правила. Этот предел срабатывает только в том случае, если в облаке выполняется более 2000 правил в час и более 5000 выполнений правил в час на сервере) |
|
Обнаружение петли |
10 |
Это контролирует, сколько раз правило может запускать себя (или другие правила) в быстрой последовательности, прежде чем выполнение будет остановлено и помечено как LOOP (Петля). |
Если вы используете последнюю версию Automation for Jira Server, вы можете использовать триггер нарушения лимита обслуживания, чтобы настроить правило автоматизации для отправки уведомлений, когда вы собираетесь нарушить одно из указанных выше лимитов по времени обработки.
Нарушение лимитов
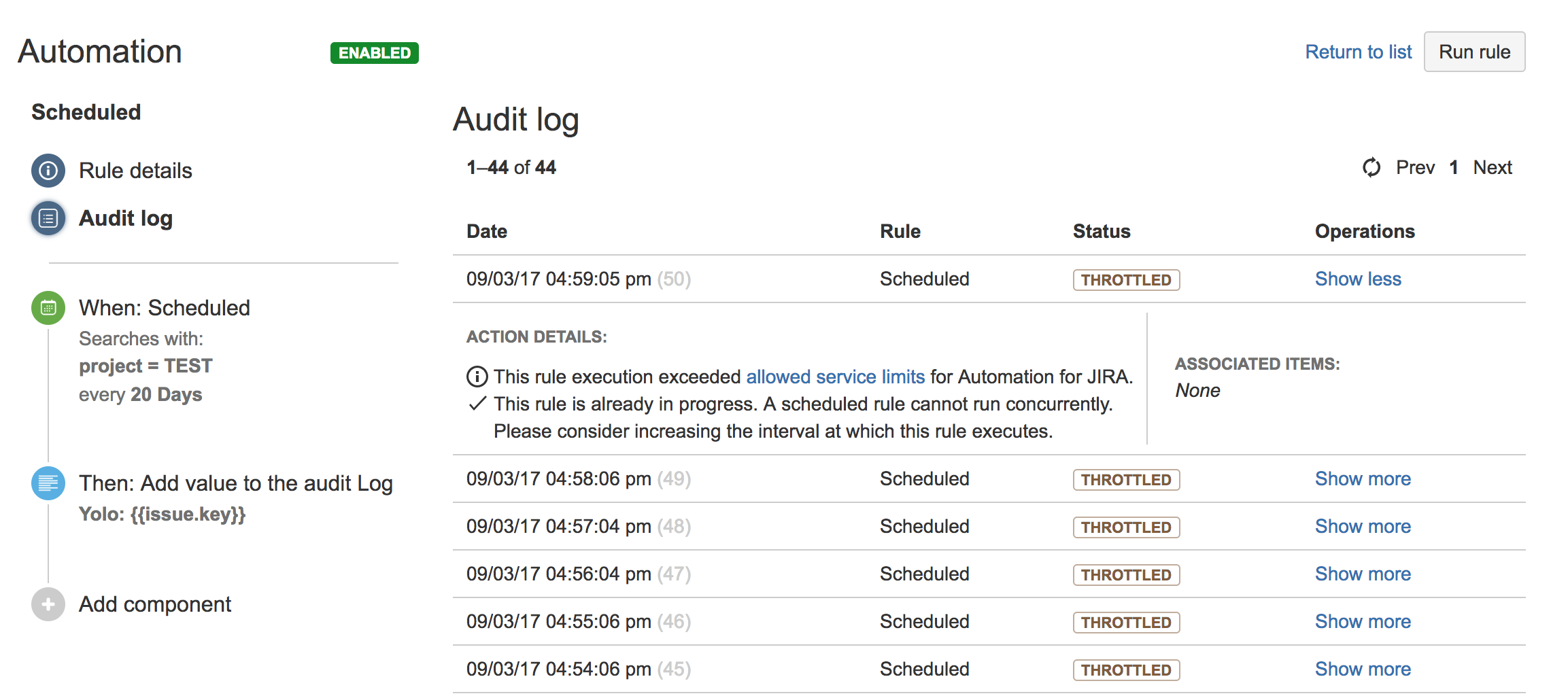
Если в журнале аудита вы видите подобные ошибки, значит, вы достигли пределов:
- Статус элемента аудита УСКОРЕННЫЙ (THROTTLED)
- Элемент аудита содержит одно из:
- Это правило автоматизации потратило больше разрешенного общего времени на обработку в последний день. Максимально допустимое время обработки в течение дня (в минутах):
- Автоматизация для Jira превысила максимально допустимое количество выполнений правил за последний час
- Поиск JQL в этом правиле автоматизации превысил максимально допустимое количество задач, извлекаемых за один поиск. Обработаны только первые задачи до следующего лимита:
Когда правило выходит за пределы установленного предела, журнал аудита содержит дополнительную информацию:
На основе сведений, представленных в журнале аудита, вы можете предпринять несколько шагов, чтобы убедиться, что ваши правила не достигают допустимых пределов, например:
- Уменьшите интервал выполнения запланированного правила. Например, правило следует выполнять только каждый час, а не каждые 5 минут.
- Ограничьте свой JQL-запрос поиском только тех задач, которые вам интересны. Например, убедитесь, что время обновления задачи находится в определенном диапазоне (например, обновлено> -1w, чтобы включить только задачи прошлой недели).
- Разделите правило автоматизации на несколько правил, если вам нужно больше компонентов для каждого правила.
- Для крупных разовых операций, требующих редактирования нескольких тысяч задач, используйте функцию массового изменения Jira.
Повышение лимитов услуг
Вы можете изменить эти значения через REST API.
Используйте вызов REST для увеличения лимитов
Во-первых, выясните, какие у вас текущие ограничения, используя этот HTTP-вызов REST:
https://YOUR_JIRA_INSTANCE_URL/rest/cb-automation/latest/configuration/property:
{
"max.processing.time.per.day": "3600",
"rule.rate.per.five.second": "2",
"short.scheduled.interval.issue.limit": "1000",
"max.rules.per.hour": "5000",
"max.issues.per.search": "1000",
"max.queued.items.per.rule": "25000"
}
|
Свойство |
Описание |
|
max.processing.time.per.day |
Это максимальное количество секунд, которое одно правило может потратить на обработку за последние 24 часа. То есть, если правило выполняется в среднем 1 минуту и выполняется 60 раз в течение 24 часов, то это правило будет ограничено. |
|
rule.rate.per.five.second max.rules.per.hour |
Они контролируют, сколько правил может быть обработано. Они работают так: Если за последние 5 секунд произошло больше выполнений, чем указано в rule.rate.per.five.second, проверяется, были ли достигнуты максимальные ограничения в час для этого клиента. Это гарантирует, что в случае всплеска активности они будут ограничены. Однако, если после этого всплеска активность возвращается в нормальное русло, а правила действуют медленно, они немедленно выполняются снова. Например, у вас есть правило A, сработавшее 10 раз за последние 5 секунд: проверяется, сколько раз сработали все правила за последний час. Если это значение превышает 5000 для экземпляра, то выполнение этого правила регулируется. |
|
max.issues.per.search |
Это контролирует, сколько задач обрабатывается в целом любым триггером, запускающим поиск (например, триггером JQL или Incoming Webhook). По умолчанию используется свойство конфигурации jira.search.views.default.max, которое можно настроить отдельно. |
|
short.scheduled.interval.issue.limit |
Этот лимит используется для сокращения интервала, с которым может выполняться поиск крупных задач с использованием запланированного триггера. Если запрос возвращает больше задач, чем этот лимит, пользовательский интерфейс показывает предупреждение и разрешает расписания не более 4 раз в течение 24 часов. Это мягкий лимит, то есть он применяется только при настройке правила. |
|
automation.processing.thread.pool .size.per.node |
Это немного отличается от свойств выше. Он определяет количество правил обработки потоков вне очереди на сервере Jira. По умолчанию это 4 потока на сервер (или на узел в центре обработки данных). Как правило, этого должно быть достаточно для большинства случаев. Если вы видите медленное выполнение правил, вы можете увеличить это число до 8 потоков. Предупреждение: увеличение этого значения может иметь противоположный эффект и привести к снижению производительности, если ваша БД или сервер приложений не может справиться с возросшей нагрузкой. Увеличивайте это значение только в том случае, если вы уверены, что ваша инфраструктура справится с этим. |
|
max.queued.items.per.rule |
Для получения дополнительной информации см. Ограничения на обслуживание в очереди. |
|
max.queued.items |
Подобно max.queued.items.per.rule, но применяется глобально для вашего экземпляра Jira во всех действующих правилах автоматизации. |
|
max.rule.execution.loop.depth |
Это контролирует, как обнаруживаются петли. Правилу (или правилам) будет разрешено запускать само себя или другие правила и создавать цепочку выполнения до этого лимита. По умолчанию это 10. Таким образом, в простейшем случае, если у вас есть правило, которое запускается немедленно, тогда ему будет разрешено выполняться 10 раз, прежде чем его выполнение будет остановлено и помечено как LOOP в журнале аудита. |
Чтобы установить одно из этих свойств, используйте этот вызов REST (Content-Type должен иметь значение application / json):
PUT https://<your Jira instance url>/rest/cb-automation/latest/configuration/property
{
"key": "max.processing.time.per.day",
"value": "10000"
}
Пример команды curl:
curl -X PUT -H 'Content-type: application/json' \
-d '{"key": "max.rules.per.hour", "value": "10000"}' \
https://your-instance.com/rest/cb-automation/latest/configuration/property
Лимит обслуживания элементов в очереди
Automation for Jira Server использует очередь обработки правил для управления выполнением правил автоматизации в вашем экземпляре. Jira имеет ограниченные возможности для обслуживания запросов от пользователей в браузере, а также для выполнения «фоновых» служб, таких как правила автоматизации. Чтобы гарантировать, что Jira не будет перегружена и не будет отвечать на запросы, выполнение правил автоматизации ставится в очередь, а количество элементов, параллельно обрабатываемых вне очереди, ограничено. По умолчанию в облаке только 8 элементов обрабатываются параллельно для каждого хоста Jira и 6 параллельных потоков на сервере (на каждый узел для конфигураций центра обработки данных).
Создатель правил автоматизации очень мощный и позволяет пользователям настраивать правила, которые делают что угодно. Это может привести к очень дорогостоящим правилам. Давайте рассмотрим конкретный сценарий с этими примерами задач:
- ABC-120 - родительская задача разработки с типом задачи «Задача»
- ABC-121 - Подзадача 1
- ABC-122 - Подзадача 2
- ABC-123 - Подзадача 3
- ABC-124 - Подзадача 4
- ABC-125 - Подзадача 5
- ABC-130 - Еще одна задача родительской разработки с типом задачи «Задача»
- ABC-131 - Подзадача 1
- ABC-132 - Подзадача 2
- ABC-133 - Подзадача 3
- ABC-134 - Подзадача 4
- ABC-134 - Подзадача 5
Теперь рассмотрим следующее правило:
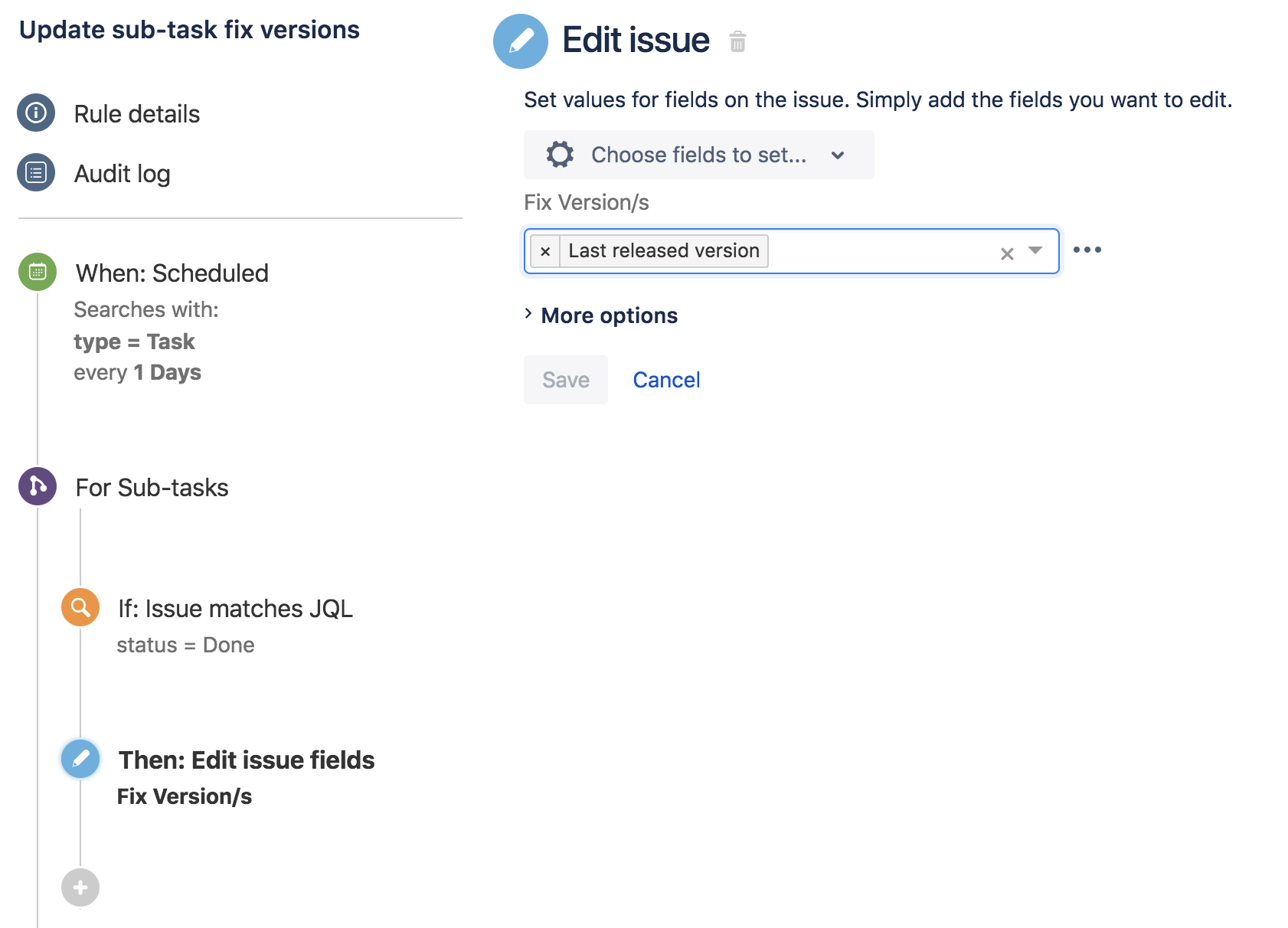
Это простое правило приводит к тому, что в очереди автоматизации оказывается 13 отдельных элементов. Давайте разберемся с этим:
1 элемент поставлен в очередь на выполнение начального запланированного триггера для запуска поиска
2 элемента поставлены в очередь для соответствующих родительских проблем ABC-120 и ABC-130
Затем для каждого из этих элементов соответствующая ветвь задачи ставит в очередь по 5 элементов.
Итак, получается 1 + 2 + 5 + 5 = 13 элементов.
Вы можете видеть, что эти типы правил могут быстро добавиться к большому количеству элементов в очереди, если, например, начальный запланированный триггер соответствует множеству задач или если связанные ветви задач соответствуют множеству задач (связанные ветви задач также могут выполнять поиск для проблем с JQL!).
Почему много элементов в очереди плохо?
Инфраструктура обрабатывает множество элементов в очереди. Однако единые правила, которые вставляют множество элементов, пагубно сказываются на производительности Automation for Jira. Мы видели, как правило одного клиента вставляет более 100 000 элементов в очередь автоматизации облака, и все 8 процессоров для этого клиента часами обрабатывали эту очередь, задерживая выполнение всех остальных правил.
Чтобы в какой-то степени обойти это, выполнение определенных правил имеет приоритет (например, сначала выполняются триггеры ручных правил), но этот подход может только зайти так далеко.
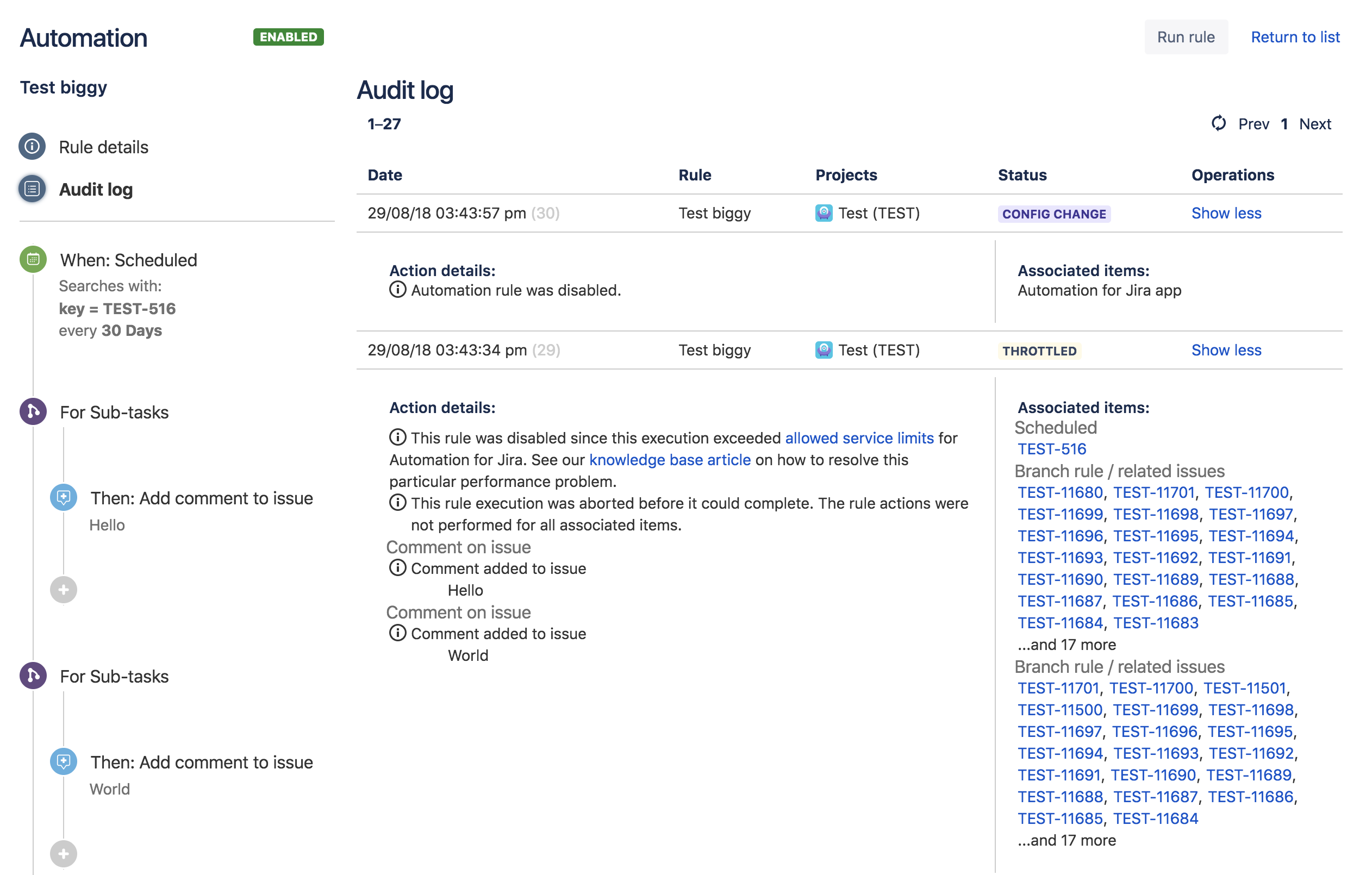
Ускорение Throttle и отключение
Когда правило добавляет чрезмерное количество элементов в очередь в конце своего выполнения, это записывается в журнал аудита, а затем правило отключается, чтобы предотвратить выполнение в будущем:
Какие типы правил могут вызвать это?
Правила с множеством связанных веток задач, где каждая связанная ветка задач соответствует значительному количеству задач. Например,
- Запланированный триггер, соответствующий 100 задачам
- Ветка связанных задач, соответствующая 50 задачам
- Другая ветка связанных задач, которая соответствует 80 задачам
В результате получается (приблизительно) 13 000 элементов (100 * 50 + 100 * 80).
Правило с множеством связанных веток задач (для имитации условий):
- Триггер: проблема обновлена
- Связанная ветка с JQL: type = Баг, которая соответствует 1000 задачам
- Связанная ветка с JQL: type = Task, которая соответствует 500 задачам
- Связанная ветка с JQL: type = Feature, которая соответствует 2000 задачам
В результате получается 3500 или более элементов, в зависимости от количества филиалов (1000 + 500 + 2000).
Предотвращение
Наконец-то вы подошли к острой части! К счастью, большинство правил не выполняется для такого большого количества задач при каждом выполнении. Есть несколько способов уменьшить эту проблему:
- Убедитесь, что вы используете JQL, который ограничивает выполнение минимально возможным набором задач. Этого можно добиться несколькими способами:
- Убедитесь, что ваш поиск JQL максимально конкретен. Например. не ищите только задачи, соответствующие type = Task, если вас интересуют только задачи, которые в настоящее время «Выполняются» ("In Progress"). type = Task и status = "In Progress" было бы лучшим поиском
- Включайте только те задачи, которые изменились с момента последнего выполнения правила, установив флажок Включать только те проблемы, которые изменились с момента последнего выполнения этого правила ("Only include issues that have changed since the last time this rule executed"). Для многих правил вполне нормально работать только с этим небольшим подмножеством
- Не создавайте связанные ветки задач для «условных проверок». Таким образом, приведенное выше правило со многими связанными ветками задач, проверяющими type = Bug, type = Task и т. д., можно было бы более эффективно написать следующим образом:
- Триггер: проблема обновлена
- Связанная ветка задач с конкретным JQL, чтобы соответствовать вашим задачам (каким-то образом связанным с задачей триггера)
- В этой ветке используйте блок if / else для сопоставления в зависимости от типа задачи
В общем, цель состоит в том, чтобы уменьшить общее количество задач, извлекаемых правилом через триггер или связанные ветви задач.
По материалам Automation for Jira - Server: Service limits